

Enterprise Integration Patterns - Domain Event Design

In the first post in the series, we took a case study from Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions and looked at how we could implement it using modern serverless technologies. We considered how we could use SQS and SNS, but decided to use EventBridge and a central event bus.
In this post, we look at how we can go about identifying and designing the events that are raised and handled by the application. We consider the structure of the events, how they might evolve, and how we can handle payloads that could be potentially large and could contain sensitive information.
Full working code for this post can be found on the accompanying GitHub repo.
Case study recap
The case study we looked at is an application that acts as a loan broker. The application receives a request containing the details of the loan required via an API, and then returns the best rate to a webhook.
The following diagram shows how we use a central EventBridge event bus to implement this.
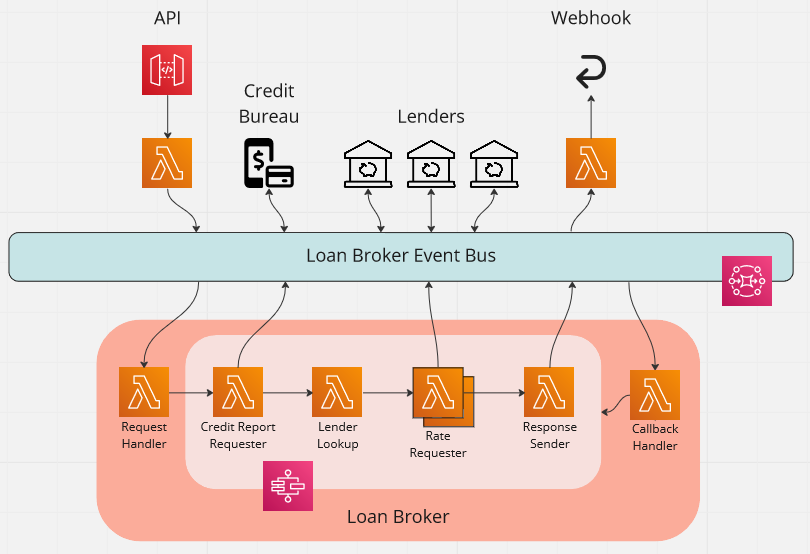
The processing of each API request is as follows:
- The API handler publishes a
QuoteSubmittedevent - The
QuoteSubmittedevent is handled and initiates a step function - The step function publishes a
CreditReportRequestedevent and pauses - The
CreditReportRequestedevent is handled, and then aCreditReportReceivedevent is published - The
CreditReportReceivedevent is handled and the step function continues - For each registered lender, a
LenderRateRequestedevent is published and the step function pauses - Each
LenderRateRequestedevent is handled, and aLenderRateReceivedevent is published - When all lenders have responded, the step function continues
- The best rate is selected and a
QuoteProcessedevent is published with the result - The
QuoteProcessedevent is handled and the webhook is called with the best rate
Event identification
Central to an event-driven architecture like this are the events themselves. In our example, these are, e.g. QuoteSubmitted, LenderRateReceived, and so on. They are what I would call domain events, in that they relate purely to the business domain and not the implementation platform.
The identification of events can come out of walking through the process being implemented, or from a more formal process. These processes could be domain-driven design (DDD) or event storming.
The key is that all event describe something happened in the past, not that anything should happen in the future. The latter is a request or command, not an event. To paraphrase the Wikipedia event storming page, an actor executes a command that results in the creation of a domain event, written in past tense.
Basic event Structure
Once we have our events, we need to think about how we structure them. This part of the post was very much inspired by the Amazon EventBridge: Event Payload Standards post by David Boyne. I would very much recommend reading that post.
In that post, the following example is given of a standard EventBridge event:
{
"version": "0",
"id": "0d079340-135a-c8c6-95c2-41fb8f496c53",
"detail-type": "OrderCreated",
"source": "myapp.orders",
"account": "123451235123",
"time": "2022-02-01T18:41:53Z",
"region": "us-west-1",
"detail": {...} // whatever we like
}
To quote the post:
The
version,account,timeandregionare all properties that AWS handles for us. That leaves core propertiesdetail,detail-typeandsourceto be defined by us.
We can populate detail-type with the event type, e.g. QuoteSubmitted or LenderRateReceived in our example, and source with a string indicating the origin of the event, e.g. LoanBroker.CreditBureau. We could just populate detail with just the data for the event. However, there is an advantage to doing something slightly different.
David's post was itself influenced by the The power of Amazon EventBridge is in its detail post by Sheen Brisals. In it, Sheen shared with us a pattern of introducing metadata within our detail object.
"detail": {
"metadata": {
...
},
"data": {
...
}
}
As the post points out:
Implementing these kinds of standards within our events can provide us with some benefits:
- Better filtering of events (we can filter on metadata as well as the event payload)
- Easier downstream processing based on metadata
- Opens the doors to more observability patterns and debugging options
Given this, let us define a TypeScript interface from which we can derive all our domain events.
export interface DomainEvent<T extends Record<string, any>> {
readonly metadata: DomainEventMetadata;
readonly data: T;
}
Here we take advantage of TypeScript's support for generics. This allows us to define the structure of all our events, without tying us to any specific type. All we ask is that the data type extends Record<string, any>. We ensure this by the use of the T extends Record<string, any> constraint.
Another TypeScript feature we take advantage of here is having readonly properties on our interface. As the post TypeScript - Interfaces with Read-Only Properties explains, having these as read-only means that the TypeScript compiler will help us treat the resulting events as immutable. This is important, as events are a record of what has happened and - as we all know - we cannot change the past.
Metadata structure
Now that we have our basic event structure, we can start to think about the metadata that we want with each event.
The first class of information relates to where the event originated. In this case, we split the information into the service that raised it and the domain which the service is part of. In our case study we have a single domain, LoanBroker, but several services, with the CreditBureau being one. We group this using a TypeScript interface as follows.
export interface EventOrigin {
readonly domain: EventDomain; // E.g. LoanBroker
readonly service: EventService; // E.g. CreditBureau
}
Why would we want to include this information? One reason is to enhance observability when we log such events. In becomes clear where the information has come from. Another reason, as we will see in a later post, is that we can add listeners to all events from either a particular service or a particular domain. Again, this can help with observability.
On the subject of observability, one of the challenges of event-driven systems is building up a picture of the flow of a request through the system. One way to do this is to use correlation and request ids.
Every call into our application will pass both a correlation and a request id in each event. The correlation id can be externally-specified, but the request id will be generated for each call. Using a correlation id in this way, allows our application to be tracked as part in longer-running sagas. For example, if a call was retried, then it may use the same correlation id. This would allow us to piece together that the two requests were related.
The final id in our context is an event id. This id is unique to each individual event. EventBridge delivers events 'at least once', which means that some events will be received more than once. To handle this scenario, the system needs to be able to behave in an idempotent manner. The event id allows event handlers to do so, by use the event id to recognise duplicate events.
With all this is mind, we create an EventContext interface with our ids.
export interface EventContext {
readonly correlationId: string; // Can be externally provided
readonly requestId: string; // Always internally generated
readonly eventId: string; // Internally generated and unique to the event
}
Now we put these interfaces together, along with a timestamp. An EventBridge event does automatically get a timestamp, but we include one here to make out metadata self-contained. If we use another transport for the event detail, then we will still have this very useful information.
export interface DomainEventMetadata
extends EventOrigin, EventContext {
readonly timestamp: Date; // Keep metadata self-contained
}
Now the detail for each of our domain events allows us see when it was raised, where it came from, and the context under which it was raised. Although we will be using EventBridge, we are not relying on EventBridge to provide any of the metadata. We could raise the same events through another messaging technology if that was desirable.
Evolving events with versioning
If there is one constant, it is change. Systems evolve over time, so it is important to bear this in mind when building them.
In the case of events, we may want to add information to them over time. In general, this will be a safe thing to do. However, this is only true if we know that all downstream systems accept new properties. This puts the emphasis on us to write event consumers to be as forgiving as possible.
However, it may be the case that at some point we need to fundamentally change the structure of an event. How can we do this without breaking something? With a distributed system, we are not able stop everything. We might have old events in-flight awaiting processing as well. So what can we do?
The solution I am proposing here was inspired by listening to the following podcast: Real-World Serverless: Event-driven architecture at PostNL with Luc van Donkersgoed
If you search for 'an interesting question about versioning' in the transcript, then you will be taken to the discussion of how versioned events can help with this scenario. The approach is to support multiple versions of the same event for a period of time. The event producer raises both event versions and event consumers match on the version to handle the appropriate version.
To do this, we extend the event metadata to include the event type and the event version as follows.
export interface EventSchema {
readonly eventType: EventType; // E.g. QuoteSubmitted
readonly eventVersion: string; // E.g. 1.0
}
export interface DomainEventMetadata
extends EventOrigin, EventContext, EventSchema {
readonly timestamp: Date;
}
This allows us to match on event version as shown below. This way we can support consumers for both the old and new versions.
export const QUOTE_PROCESSED_PATTERN_V1 = {
detail: {
metadata: {
eventType: [EventType.QuoteProcessed],
eventVersion: [{ prefix: '1.' }],
},
},
};
export const QUOTE_PROCESSED_PATTERN_V2 = {
detail: {
metadata: {
eventType: [EventType.QuoteProcessed],
eventVersion: [{ prefix: '2.' }],
},
},
};
Now we can have the event producer raise both the old and new versions of the event. This might be a temporary solution until we remove consumers of the old event version, or it could be a permanent state of affairs. With event versioning, we have the choice.
Passing large and sensitive payloads
Another consideration with our events is the size of the payload. Although in the example code the request is small, in reality such requests can be much larger in size. As the AWS article Calculating Amazon EventBridge PutEvents event entry size states, the total entry size must be less than 256KB. The solution is also mentioned:
If the entry size is larger than 256KB, we recommend uploading the event to an Amazon S3 bucket and including the Object URL in the PutEvents entry.
Of course, each downstream component will need access to the data, and so they will need access to the S3 bucket. However, this introduces a form of coupling. If we decided to change the bucket location, then we would have to find all the downstream components and changes those too.
The solution is to use presigned URLs. These allow us to implement the Claim Check pattern, where we generate a short-lived URL that only allows read access to the event data. We do this as follows:
await s3
.putObject({
Bucket: bucketName,
Key: key,
ACL: 'bucket-owner-full-control',
Body: data,
} as PutObjectRequest)
.promise();
const dataUrl = await s3.getSignedUrlPromise('getObject', {
...s3Params,
Expires: expirySeconds ?? 60,
});
We can then pass the dataUrl value in our event and use it to get the data. In our case, we created a function, fetchFromUrlAsync to do this.
import fetch from 'node-fetch';
export const fetchFromUrlAsync = async <T>(url: string): Promise<T> => {
const fetchResponse = await fetch(url);
return (await fetchResponse.json()) as T;
};
This approach has a secondary benefit. Our events are passing PII (personally identifiable information), which needs very careful management. It is very easy for this information to make its way into logs, where it can leak out with very serious consequences. By using the approach outlined here, the events only ever contain a URL which can safely be logged by any component.
Summary
In this post we looked at how we can identify and structure our events. Key to this is having separate sections for the metadata and data. We can then build on this by including context, correlation, and version information in the metadata. Finally, we looked at how the Claim Check pattern can allow us to pass large payloads and also avoid logging sensitive data.
Links
- Build Cloud-Native Apps with Serverless Integration Testing
- Amazon EventBridge event patterns
- Amazon EventBridge now supports enhanced filtering capabilities
- The Value of Correlation IDs
- The power of Amazon EventBridge is in its detail
- Amazon EventBridge events
- How to publish large events with Amazon EventBridge using the claim check pattern




