

Serverless integration testing with CDK - Part 1
Constructing a way forward

From my own experience and that I have read of others, one of the biggest challenges of serverless is how to test. Beyond unit testing, do you try to replicate cloud infrastructure locally or do you rely on high-level end-to-end tests? With multiple resources interacting asynchronously, how can you develop repeatable, meaningful tests? Here I ponder how we might take advantage of the AWS CDK to help. Using it to package our serverless applications into units that can be independently deployed, tested, and then torn down.
All the code for this post is available on GitHub.
The system under test
For this post, let us consider a system that does a simplified affordability calculation for a loan application. The system contains a number of configurations and a number of scenarios. A configuration contains a set of values that are used in the affordability model, such as to specify how much of any overtime income is to be used. A scenario contains the details supplied by the loan applicants, such as a breakdown of the applicants income. The system automatically calculates the results for each combination of configuration and scenario whenever a new one is added or an existing one is amended.
The system revolves around a bucket that contains JSON files with the following structure:
{
"header": {
"fileType": "Configuration|Scenario|Result",
"name": "E.g. High Risk Scenario"
},
"body": {
<any>
}
}
The system only recalculates when the body contents of Configuration or Scenario files are updated. Changing the header details does not cause any recalculation. Note, one assumption here is that the fileType is never changed once set.
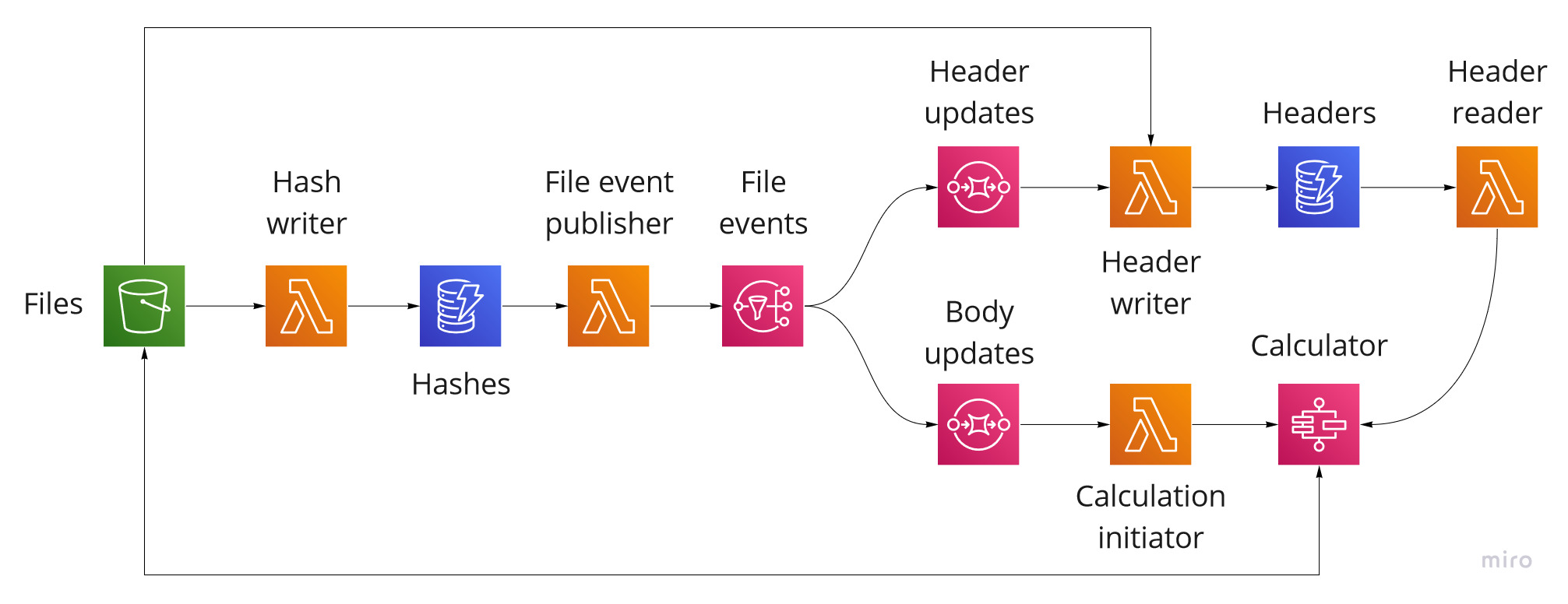
The system design is as follows:
The diagrams for this post were created using the excellent Miro tool.
When a file is added or updated to the Files bucket, an event is raised. The Hash writer Lambda function handles this event and calculates hashes for the header and body of the file. It then writes these to the Hashes DynamoDB table. The Hashes table raises change events that are then handled by the File event publisher Lambda function. The File event publisher function processes these events and sends notifications of the following format to the File events SNS topic.
{
"eventType": "Create|Update",
"s3Key": "E.g. Configuration_7Jk0Sf5JsDPZt5skWFyNR.json",
"fileType": "Configuration|Scenario|Result",
"contentType": "Header|Body"
}
Note, for the purposes of simplicity,
Deleteevents are not being considered in this example.
The Header updates SQS queue subscribes to the File events SNS topic for events with a contentType of Header. The Header writer Lambda function processes messages from the Header updates queue and retrieves the header from the Files bucket. The Header writer function then writes the an entry of the following format to the Headers DynamoDB table.
{
"fileType": "Configuration|Scenario|Result",
"s3Key": "E.g. Configuration_7Jk0Sf5JsDPZt5skWFyNR.json",
"name": "E.g. High Risk Scenario"
}
The Headers table is configured with fileType as the partition key and s3Key as the sort key. The Header reader Lambda function encapsulates access to the Headers table. It takes requests of the following format:
{
"fileType": "Configuration|Scenario|Result"
}
And returns responses as follows:
{
"headers": [
{
"fileType": "Configuration|Scenario|Result",
"s3Key": "E.g. Configuration_7Jk0Sf5JsDPZt5skWFyNR.json",
"name": "E.g. High Risk Scenario"
}
]
}
The final part of the system is the calculator. The Body updates SQS queue subscribes to the File events SNS topic for events with a contentType of Body. The Calculation initiator Lambda function processes messages from the Body updates queue and retrieves the associated file from the Files bucket. The header is then passed to the Calculator step function, which uses the Header reader function to work out the combinations to calculate, before performing each calculation and putting the results in the Files bucket.
Note, in a production system we would want to add appropriate dead letter queues and other error handling. These have been left out of the example for simplicity.
Testing
Not one part of the system we have designed is particularly complicated. In fact, the Lambda functions are going to be very simple indeed. So simple in fact, that we might query the value in building and maintaining unit tests for them. As with systems of this type, the functionality emerges from the interaction between the various simple resources. Given this, it seems reasonable to target our testing on verifying that those resources work together as expected.
One way to approach this is to break the system down as follows:
- Event publisher: subscribes to events from an S3 bucket, reads the file contents, and raises change events to an SNS topic
- Header index: subscribes to change events from an SNS topic, reads an S3 bucket, and exposes an API for listing the file headers
- Result calculator: subscribes to change events from an SNS topic, uses an API to list the file headers, reads files from an S3 bucket, calculates the results and puts them in the S3 bucket
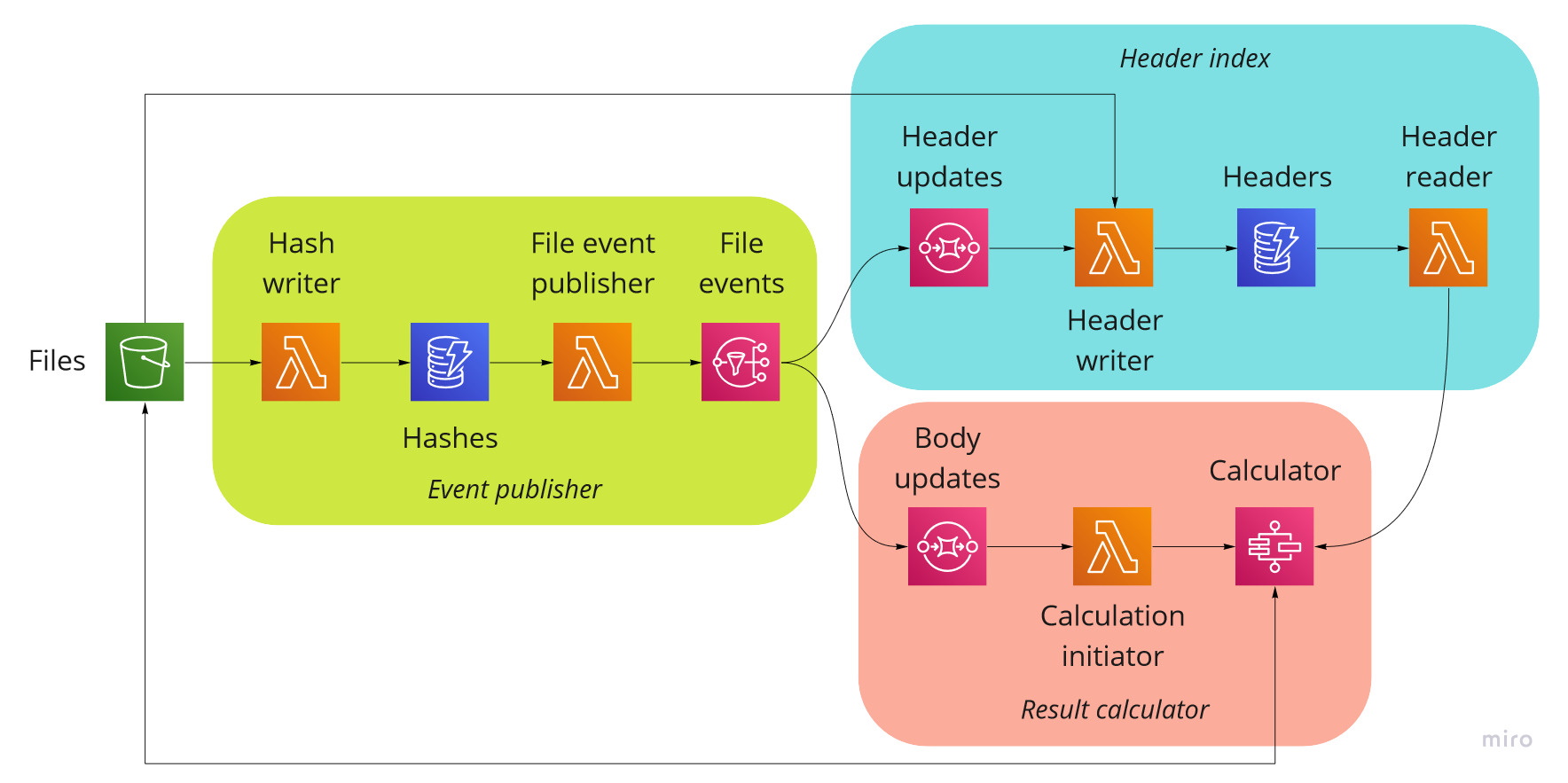
With the system broken down like this, we can create CDK constructs for each part and then create individual test stacks to deploy them for testing in isolation.
Let us first consider the Event publisher construct. To the outside world, it takes in an S3 bucket and exposes an SNS topic. With this in mind, we can create the following minimal implementation. In CDK, the pattern is to provide inputs as properties on the props passed into the constructor, and to expose outputs as public properties on the construct itself.
export interface FileEventPublisherProps {
fileBucket: s3.Bucket;
}
export default class FileEventPublisher extends cdk.Construct {
readonly fileEventTopic: sns.Topic;
constructor(scope: cdk.Construct, id: string, props: FileEventPublisherProps) {
super(scope, id);
this.fileEventTopic = new sns.Topic(this, `${id}FileEventTopic`, {
displayName: `File event topic for ${props.fileBucket.bucketName}`,
});
}
}
With this construct, we can now create a test stack that will wire up the inputs and outputs of the construct to test resources. In this case, an S3 bucket and a Lambda function.
For the Lambda function, we create one based on inline code that simply logs out the event for inspection. For the S3 bucket, we use a handy CDK property called autoDeleteObjects. Setting this to true creates a Lambda function that is triggered when the bucket is removed from the stack or when the stack is deleted. This function deletes all objects in the bucket. Having this on test buckets allows us to better clean up after ourselves.
export default class FileEventPublisherTestStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string) {
super(scope, id);
const testBucket = new s3.Bucket(this, 'TestBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
const testSubscriber = new lambda.Function(this, 'TestSubscriber', {
handler: 'index.handler',
runtime: lambda.Runtime.NODEJS_12_X,
code: lambda.Code.fromInline(
`exports.handler = (event) => { console.log(JSON.stringify(event, null, 2)) }`
),
});
const sut = new FileEventPublisher(this, 'SUT', {
fileBucket: testBucket,
});
sut.fileEventTopic.addSubscription(new subscriptions.LambdaSubscription(testSubscriber));
}
}
The stack can then be deployed as part of a CDK App as follows.
const app = new cdk.App();
new FileEventPublisherTestStack(app, 'FileEventPublisherTestStack');
We now have an S3 bucket to drop test files into, and we have a Lambda function that outputs the resulting events for us to verify. If we are using VS Code and the AWS Toolkit, then we can do both of these things without leaving our editor whilst we develop and test the functionality. Of course, at the moment, dropping things into the bucket has no effect.
I have left out the implementation of the fileHashWriter and fileEventPublisher, but if you are interested then they are available in the GitHub repo. With the functions defined, I created a utility function for including these as part of a construct. It uses the NodejsFunction construct which creates a Node.js Lambda function bundled using esbuild. As well as bundling the function, it also defaults to setting AWS_NODEJS_CONNECTION_REUSE_ENABLED environment variable to 1, to automatically reuse TCP connections when working with the AWS SDK for JavaScript.
private newFunction(
functionId: string,
functionModule: string,
environment: Record<string, any>
): lambda.Function {
//
const functionEntryBase = path.join(__dirname, '..', '..', '..', 'src', 'functions');
return new lambdaNodejs.NodejsFunction(this, functionId, {
runtime: lambda.Runtime.NODEJS_12_X,
entry: path.join(functionEntryBase, `${functionModule}.ts`),
handler: 'handler',
environment,
});
}
With this utility function in place, we can add the other parts to the FileEventPublisher construct. I didn't do this all in one step. First, I created an inline version of each function and tested that it was wired up correctly. I did this by uploading to the bucket using the AWS Toolkit and then viewing the CloudWatch logs, again via the AWS Toolkit. Although deploying wasn't exactly speedy, it wasn't too bad and it was feasible to develop and test without recourse to unit tests.
Note: I still think unit tests have a big part to play in serverless development. However, they have their limits and sometimes they are so simple that covering them via integration tests would be sufficient IMHO.
The final version of the FileEventPublisher was as follows.
export default class FileEventPublisher extends cdk.Construct {
readonly fileEventTopic: sns.Topic;
constructor(scope: cdk.Construct, id: string, props: FileEventPublisherProps) {
super(scope, id);
this.fileEventTopic = new sns.Topic(this, `${id}FileEventTopic`, {
displayName: `File event topic for ${props.fileBucket.bucketName}`,
});
// The table to hold the hashes of the files sections
const fileHashesTable = new dynamodb.Table(this, 'FileHashesTable', {
partitionKey: { name: 's3Key', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'sectionType', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES,
});
// The function that is notified by the bucket and writes the hashes to the table
const hashWriterFunction = this.newFunction('FileHashWriterFunction', 'fileHashWriter', {
FILE_HASHES_TABLE_NAME: fileHashesTable.tableName,
});
props.fileBucket.grantRead(hashWriterFunction);
props.fileBucket.addEventNotification(
s3.EventType.OBJECT_CREATED,
new s3n.LambdaDestination(hashWriterFunction)
);
fileHashesTable.grantWriteData(hashWriterFunction);
// The function to receive stream events from the hashes table and publish event to the topic
const fileEventPublisherFunction = this.newFunction(
'FileEventPublisherFunction',
'fileEventPublisher',
{
FILE_EVENT_TOPIC_ARN: this.fileEventTopic.topicArn,
}
);
fileEventPublisherFunction.addEventSource(
new lambdaEvents.DynamoEventSource(fileHashesTable, {
startingPosition: lambda.StartingPosition.TRIM_HORIZON,
})
);
this.fileEventTopic.grantPublish(fileEventPublisherFunction);
}
}
Now, manually testing the deployed functionality is fine, but what we should be striving for are some repeatable tests that can be automated. That will be the subject of Part 2 in this series.




