

Step Function Errors Should Be Errors
Think before you use errors for flow control

In this post, we shall see the consequences and limitations of using step function errors as flow control.
See the accompanying GitHub repo for working code examples.
TL;DR
- Be wary when using step functions errors for flow control in step functions
- After throwing and catching an error, only the inputs and the basic error details are available
Our inheritance
We inherited a codebase that contained a step function which was asynchronously invoked from an API Gateway request. The step function performed validation on the request, before proceeding to processing the request if the validation was successful. When the validation failed, either due to schema errors or due to the content of the request, an error was thrown by the Lambda function. These errors were caught by the step function and, depending on the name of the error, the step function invoked a DynamoDB integration task to update a table with the result. Users of the API could then use another API call to query the state of the request.
A simplified version is shown below:
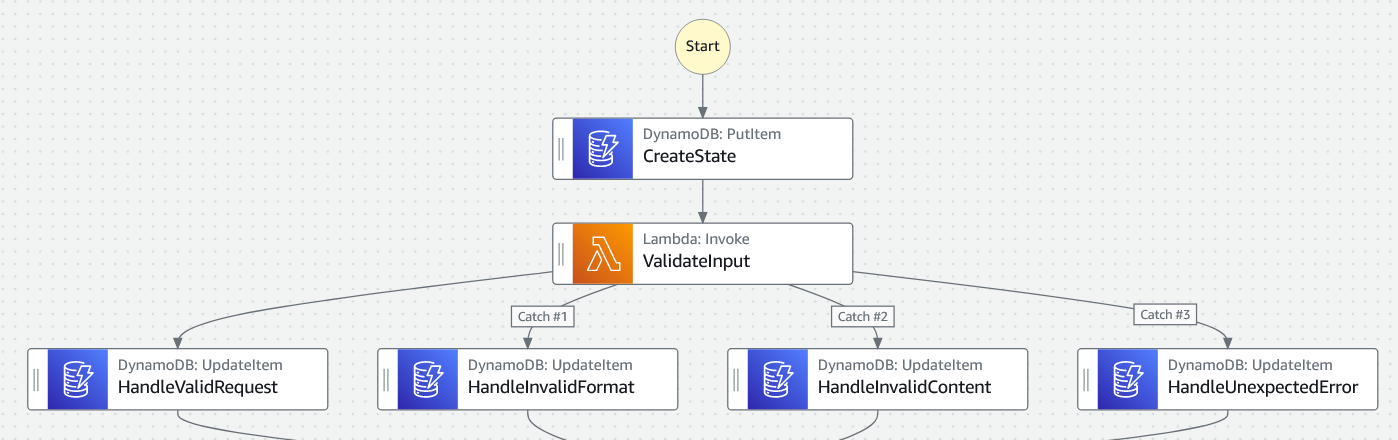
Improving things for our users
Users don't always get things right, so it was common for requests to fail. In particular, they would fail for one of the validation reasons. Whilst the underlying reasons for the failures were logged to CloudWatch, it quickly became a pain to keep looking them up whenever a user of the API suffered from a failure.
To provide better feedback for our users, we decided to add the validation errors to the result table. The users could then query this table via the API to understand why their request had failed, and all without bothering us.
The only problem was, at the point the table was being updated, we had no way of accessing the validation failures.
Post-error step function context
The problem was that after an error has been handled by a step function, only the following is available:
- The inputs to the step function
- The error type
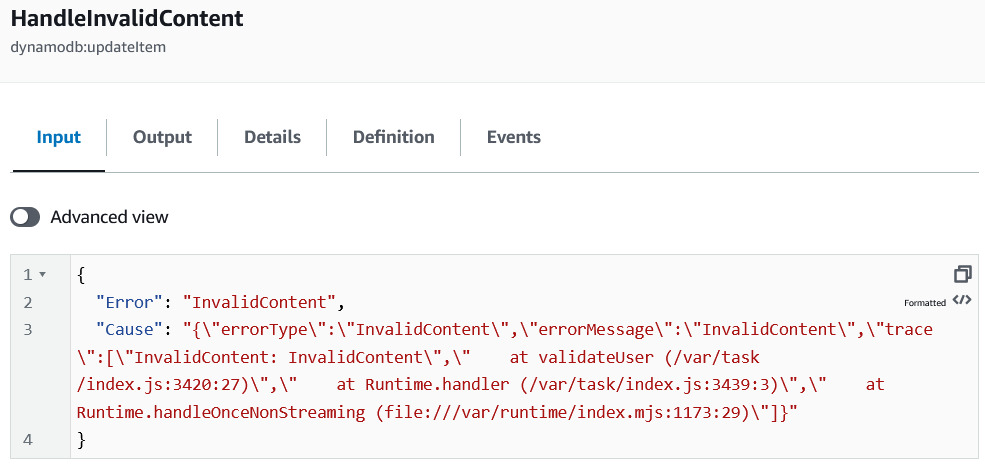
This makes sense, as there can be no guarantee of the state once an error occurs. The inputs never change, so it is safe to access their values, but it is not safe to access anything else apart from the type of error.
This means that it isn't possible to pass structured information into the error handlers. Which happened to be exactly what we needed to do if we were to extend the DynamoDB integrations to store the extra details.
Are these really errors?
It is somewhat a matter of opinion, but I would argue that neither validation failure is a true error. I say this, as we would expect both scenarios to occur in normal operations. The use of throwing and catching errors in this case looked to me like it was done as a convenience.
To resolve the issue, the validation Lambda function was updated to add the errors directly to the table. This took advantage of the fact that the relevant item was already present and that the DynamoDB integration would not overwrite any added errors. This allowed us to avoid changing the flow of the step function, but came at the cost of increasing the responsibility of the validation function.
A better approach
I would argue that the validation step should produce a validation result.
interface ValidationResult {
user?: User;
formatErrors?: ZodIssue[]; // The errors from using the zod npm package
contentErrors?: string[];
}
function validateUser(event as any): ValidationResult {
// <snip>
}
export const handler = async (
event: Record<string, any>
): Promise<ValidationResult> => {
return validateUser(event);
};
With this, we can then rework the step function with an additional choice step, as shown below:
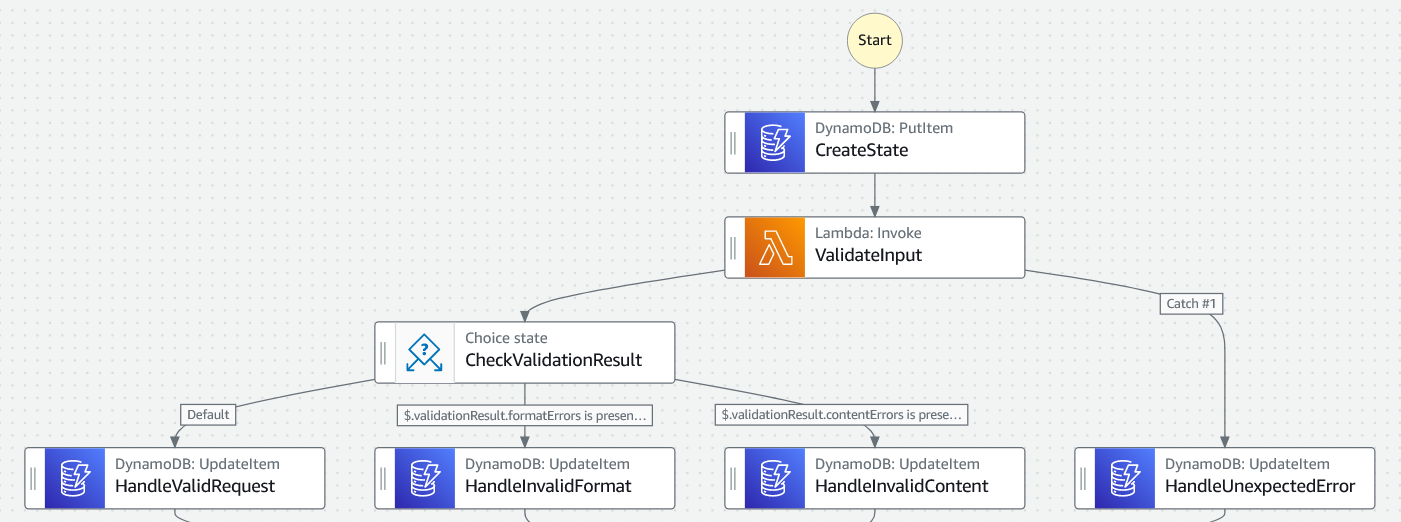
Now the DynamoDB integrations can access the relevant details. For example, for format errors.
{
"Key": {
"key": {
"S.$": "$$.Execution.Input.requestId"
}
},
"TableName": "<snip>",
"ExpressionAttributeNames": {
"#status": "status",
"#formatErrors": "formatErrors"
},
"ExpressionAttributeValues": {
":status": {
"S": "InvalidFormat"
},
":formatErrors": {
"S.$": "States.JsonToString($.validationResult.formatErrors)"
}
},
"UpdateExpression": "SET #status = :status, #formatErrors = :formatErrors"
}
With this approach, the validation step is pure validation and not given a secondary responsibility of storing any validation errors.
General discussion
Consider the following C# method:
MyEntity FindMyEntity(string id);
What should the method return if there is no such instance with a matching id? Should it return null or throw an exception?
I would say it depends on the caller. If the caller cannot continue without the entity, throw an exception. If it can continue, return null. This could be catered for with the following:
MyEntity FindMyEntity(string id, bool throwExceptionIfNotFound = false);
Now the caller can control the behaviour as they need.
You could go further and return a result object.
FindResult<MyEntity> FindMyEntity(string id);
You can then explicitly check for the 'not found' scenario.
if (entityFindResult.NotFound) // ...
else // Use entityFindResult.Value
Summary
I would advise against using errors as a replacement for step function flow control using choice steps. Once the error is thrown, the current state is lost and only the error type is then available downstream.
In general, I would advise against throwing errors/exceptions/<insert your favourite language version here> as part of 'normal' processing. That is, unless the idioms of your preferred language recommend it. I have found that there are usually alternatives that make your code cleaner and more extensible.




