

Using Local Blob Storage

In the previous post in this series on creating a webhook proxy using Azure serverless technology, I added API Management in front of an Azure Function. In this post, I turn my attention to fleshing out the back-end functionality. In particular, implementing the 'store' part of the store and forward pattern and putting the received request payloads in Azure Blob Storage for subsequent processing.
A quick overview of Azure Blob Storage
Blob Storage is the Azure service that is equivalent to AWS S3, in that it is used for storing large amounts of unstructured data, such as text or binary data.
Blob Storage is composed of the following resource hierarchy:
- Storage Account: The top-level resource, providing a globally-unique namespace in Azure for your storage data.
- Container: Provides a grouping of a set of blobs.
- Blob: The fundamental storage entity in Azure Blob Storage. There are three types of blobs:
- Block Blobs: Used for storing text or binary files, like documents, media files, etc.
- Append Blobs: Optimized for append operations, making them ideal for scenarios like logging.
- Page Blobs: Designed for frequent read/write operations.
Access to blobs and containers is controlled through:
- Access Keys: Storage account keys that give full privileges to the storage account.
- Shared Access Signatures (SAS): Provides restricted access rights to containers and blobs, with a defined start time, expiry time, and permissions.
- Azure Active Directory (Azure AD): For RBAC (role-based access control) to manage and control access.
There are other aspects to Blob Storage, such as:
- Access Tiers: To store data based on the frequency of access, such as 'Hot', 'Cool', and 'Archive'.
- Lifecycle Management: Automating the process of moving blobs to cooler storage tiers or deleting old blobs that are no longer needed.
- Security: Options regarding encryption at rest and in transit.
- Redundancy: Options such as 'Locally Redundant Storage (LRS)', 'Zone-Redundant Storage (ZRS)', and 'Geo-Redundant Storage (GRS)'.
Creating our containers
Visual Studio 2022 ships with the Azurite emulator for local Azure Storage development, so I already had it installed. However, if you're running an earlier version of Visual Studio, you can install Azurite by using either Node Package Manager (npm), DockerHub, or by cloning the Azurite GitHub repository.
Another useful tool is the Azure Storage Explorer. This allows you to upload, download, and manage Azure Storage blobs, files, queues, and tables as well as configuring storage permissions and access controls, tiers, and rules.
One thing I did note was that to start the emulator, I needed to run the function app using F5. This started the Azurite background process, which then showed up in the storage explorer as follows:
If I didn't do this, the storage explorer would tell me to install Azurite.
With the emulator up and running, the next step was to create some containers for the payloads. I had decided to split the payloads into two containers, one for payloads that had passed validation (webhook-payloads-accepted) and were accepted for further processing and another for payloads that were rejected (webhook-payloads-rejected).
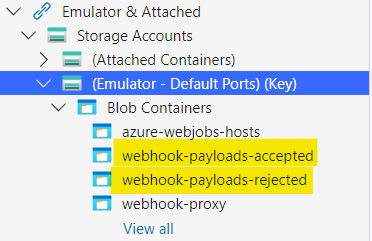
Storing the payloads
Before storing the payloads in the new containers, I needed to decide how they should be stored. Blob Storage is essentially a flat namespace, which means it doesn't have real directories or folders. However, it does support a folder-like structure using naming conventions and delimiters, typically the forward slash (/), within blob names.
Putting myself in the place of someone fielding a support query, I imagined being told that a tenant was expecting a payload from a particular third party on a specific day. With this hierarchy in mind, I decided upon the following 'folder' structure.
private static string GetBlobName(
string tenantId,
string senderId,
string messageId)
{
var blobName =
$"{tenantId}/{senderId}/{DateTime.UtcNow:yyyy-MM-dd}/{messageId}.json";
return blobName;
}
The value of messageId is globally unique and will be passed back to the caller in a custom header. This adds another possible route for debugging calls between the systems.
Now we know how we are going to store the payloads, we need to use the SDK to store them. First of all we need a BlobServiceClient instance. It can be good practice to avoid over-instantiation of SDK clients. ChatGPT seemed to think that reusing the same instance is recommended in official Azure SDK documentation to improve performance and resource utilization. For production, I would double-check this, but for now that is good enough for me and so I stored the client at a module level.
private readonly BlobServiceClient _blobServiceClient;
public BlobPayloadStore(ILoggerFactory loggerFactory)
{
_logger = loggerFactory.CreateLogger<BlobPayloadStore>();
_blobServiceClient = new BlobServiceClient("UseDevelopmentStorage=true");
}
BlobPayloadStore was registered as a singleton with the dependency injection, so there was no need to have any statics involved. I.e., in Program.cs:
.ConfigureServices(services =>
{
// <snip>
services.AddSingleton<IPayloadStore, BlobPayloadStore>();
})
This just left me the task of writing the code to upload the payloads to the appropriate containers. The result is as follows.
private async Task UploadPayloadAsync<T>(
string containerName,
string tenantId,
string senderId,
string contractId,
string messageId,
T payload) where T : PayloadBase
{
string payloadJsonString = JsonConvert.SerializeObject(payload, Formatting.Indented);
var blobServiceClient = GetBlobServiceClient();
var containerClient = blobServiceClient.GetBlobContainerClient(containerName);
var blobName = GetBlobName(tenantId, senderId, contractId, messageId);
var blobClient = containerClient.GetBlobClient(blobName);
var byteArray = Encoding.UTF8.GetBytes(payloadJsonString);
using var stream = new MemoryStream(byteArray);
await blobClient.UploadAsync(stream, overwrite: true);
}
Local testing
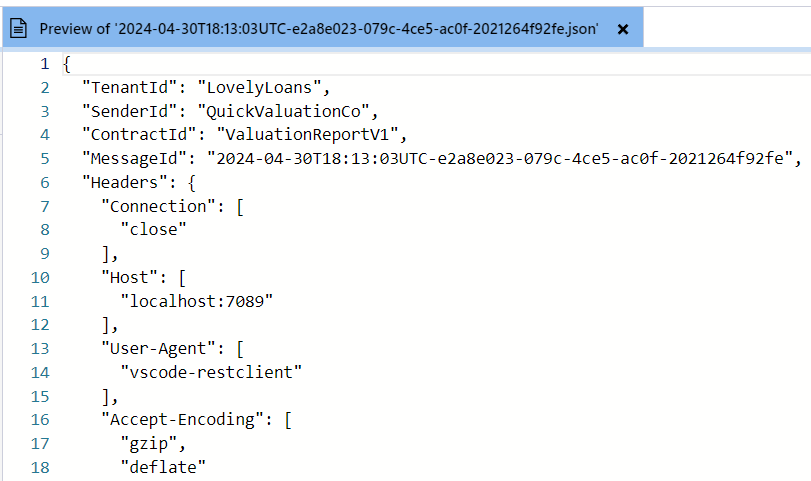
After hitting F5 to run the function, I submitted a valid request to the local endpoint. Opening up Azure Storage Explorer, I could see a blob had been added as expected to the 'accepted' container.

The Azure Storage Explorer has a handy feature to preview the contents. Using this, I inspected the contents and could see that they contained the expected details. I did note that the API key value was not present, so must have been very sensibly filtered out.
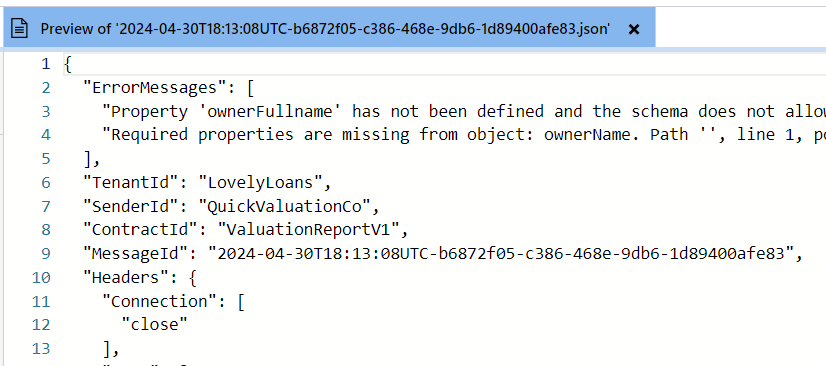
I then ran a test with an invalid payload and, sure enough, a blob was added to the rejected container.

Previewing this, I could see that the errors had been passed through as expected.
Cloud considerations
The next step is to deploy to the cloud and test there. However, this raises a number of questions.
- How should the Blob containers be exposed?
- Public vs. Private endpoints
- How should the Azure Function connect to the containers?
- Connection string?
- Managed identity?
- If using a connection string, how should it be obtained?
- Environment variable?
- Key vault?
Given these considerations, this feels like a post in itself. So I will leave it till next time.
Summary
In this post, I showed how I was able to use the local Azure development tools to implement and test storing the request payloads. However, to get the functionality deployed and working in the cloud will require some more thought and experimentation.




